
所有核心信息均来自原报告 Artificial Analysis State of AI – Q3 2025 – Highlights Edition 。Lin 师傅只做策展和解读部分。
Artificial Analysis是一家专注做独立评测与洞察的机构:既跑模型基准、也跑性能与成本对比,数据覆盖从语言模型 API 到“百万投票”的竞技场。它们的季度报告,对于工程、产品与投资从业者的决策提供重要参考。

摘要:Q3 的 AI 世界在加速
竞争更白热化 :从模型到产品,创新没有停下。xAI 已与 OpenAI、Google、Anthropic 一起挤进报告的 智能指数 第一梯队;还有十几家(多为中国团队)紧随其后。(见“编者按”和智能指数曲线)
“智能体”(Agent)成为主角 :更长的工具使用链路、更多多步任务,正成为各大实验室发力点。
图像编辑与视频生成走向大众 :尤其是 Gemini 2.5 Flash Image-preview(代号 Nano Banana )带火了“指令式”图片编辑;视频模型整体质量快进。
开放权重(Open Weights)的开源模型迎来高产季 :OpenAI 时隔 GPT-2 之后再次发布开放权重模型,与多家中国团队的领先开源权重“正面交锋”。
端到端“语音对语音”(Speech-to-Speech)可上生产 :转写、合成与原生语音推理都在成熟,企业语音智能体加速落地。
01. 行业概览(Industry Overview)
谁更“全栈”?
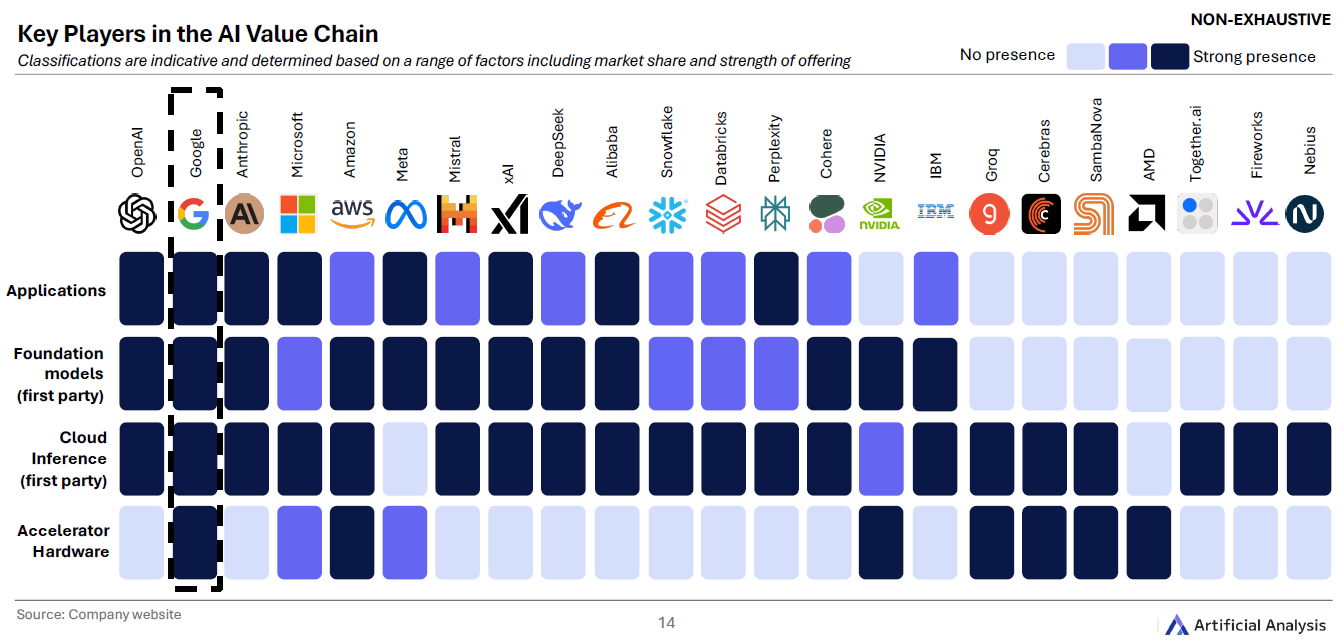
报告用一张“大地图”比了各环节的自研能力: Google 从自家 TPU 加速器到 Gemini 应用的纵向整合最深;OpenAI、xAI、Anthropic、Meta 等在模型与应用层强势,NVIDIA 则在硬件层统治力十足。(见 第14页 图)
大厂砸钱、芯片吃肉
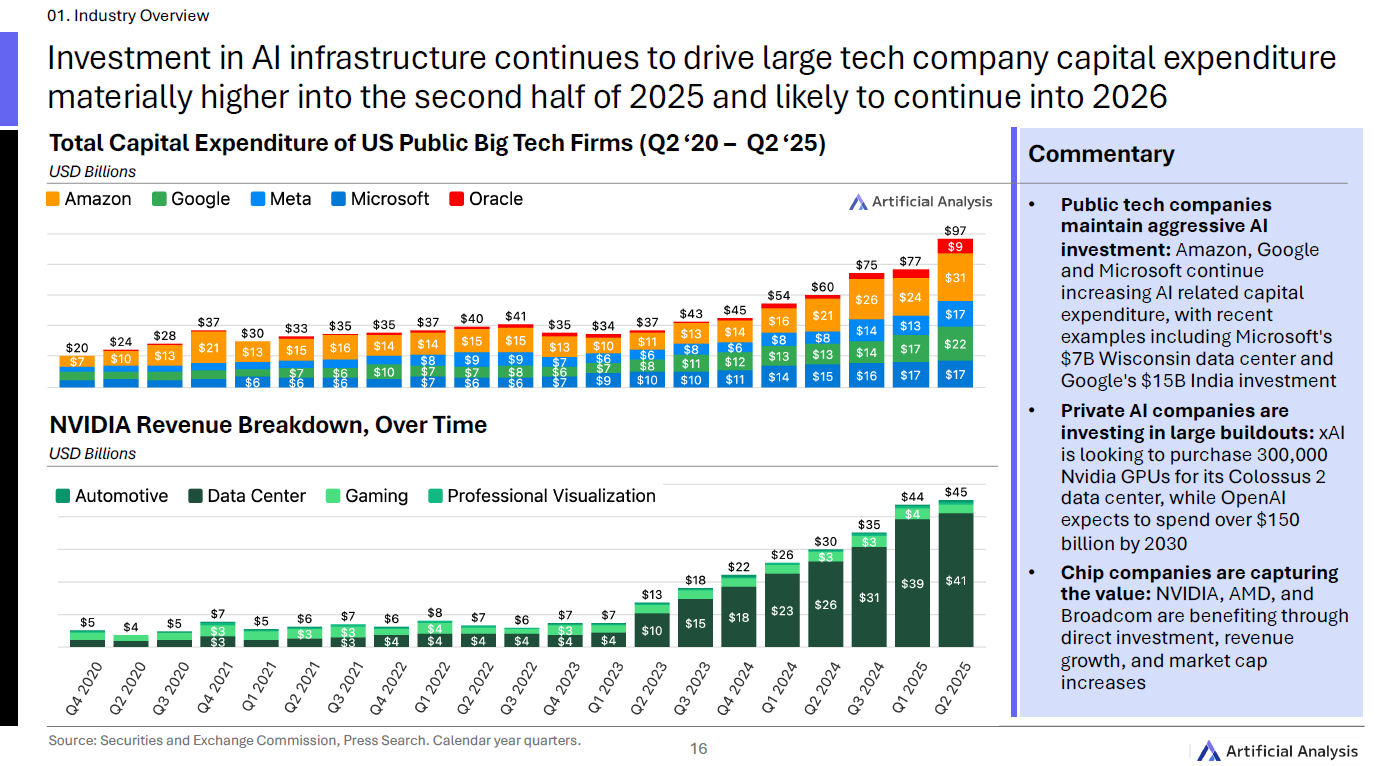
资本开支抬升 :欧美大厂把“AI 基建”当硬投入。示例: Microsoft 威斯康星数据中心 70 亿美元、Google 印度投资 150 亿美元 。同时,xAI 传出计划购入 30 万片 NVIDIA GPU;OpenAI 预计到 2030 年累计投入超 1500 亿美元 。(见 第9页 )
价值被芯片商捕获 :NVIDIA、AMD、Broadcom 都在营收与市值上受益。
02. 语言模型(Language Models)
效率提升了, 但算力更“饿”了
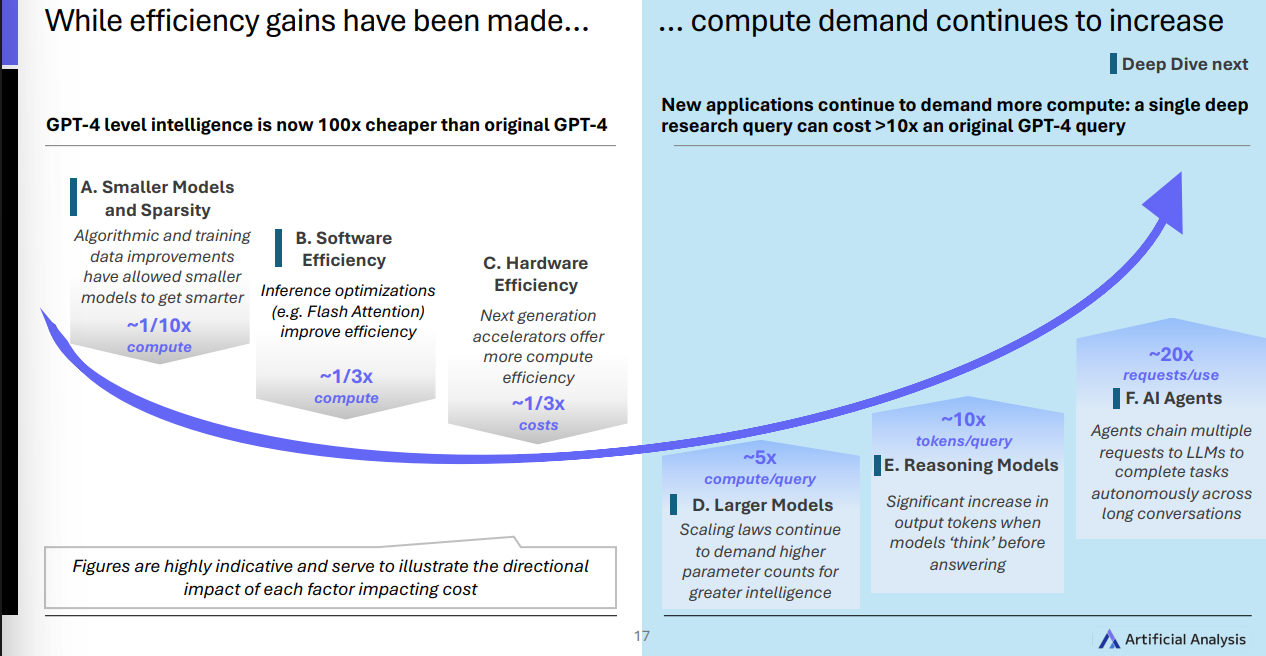
如示意图左侧图片显示,更小更聪明的模型、推理软件优化及新一代硬件,确实把 单位成本 降下来了;
但 更大的推理模型(Reasoning Models) 、更长的“思考”输出、更像“智能体”的多步任务,又把 每次任务的总算力需求 推高。
结果“ 像 GPT-4 的智能,现在比当初便宜了 100 倍,但新应用更吃算力。 ”
谁是“最聪明”的模型?
OpenAI重夺第一 : GPT-5(High) 在 Artificial Analysis Intelligence Index v3.0 上得分 68 ,领先 Grok 4(65) 、 Claude 4.5 Sonnet(Thinking, 63) 、 Gemini 2.5 Pro(60) 。(见 第18页曲线 )
美国实验室暂居前列 :OpenAI、xAI、Anthropic、Google 占据前 7;阿里(Qwen3)、DeepSeek、Mistral、Z.ai 等全球同行紧追。(见 第20页 柱状)
( 注:该“智能指数”综合 10 项评测:MMLU-Pro、GPQA Diamond、Humanity’s Last Exam、LiveCodeBench、SciCode、AIME 2025、IFBench、AA-LCR、Terminal-Bench Hard、τ²-Bench Telecom。但共同目的都是测模型“理解、推理、编程、专业知识”等综合能力。 讲白了,就是个自己造的行业指数)
谁更受企业欢迎?
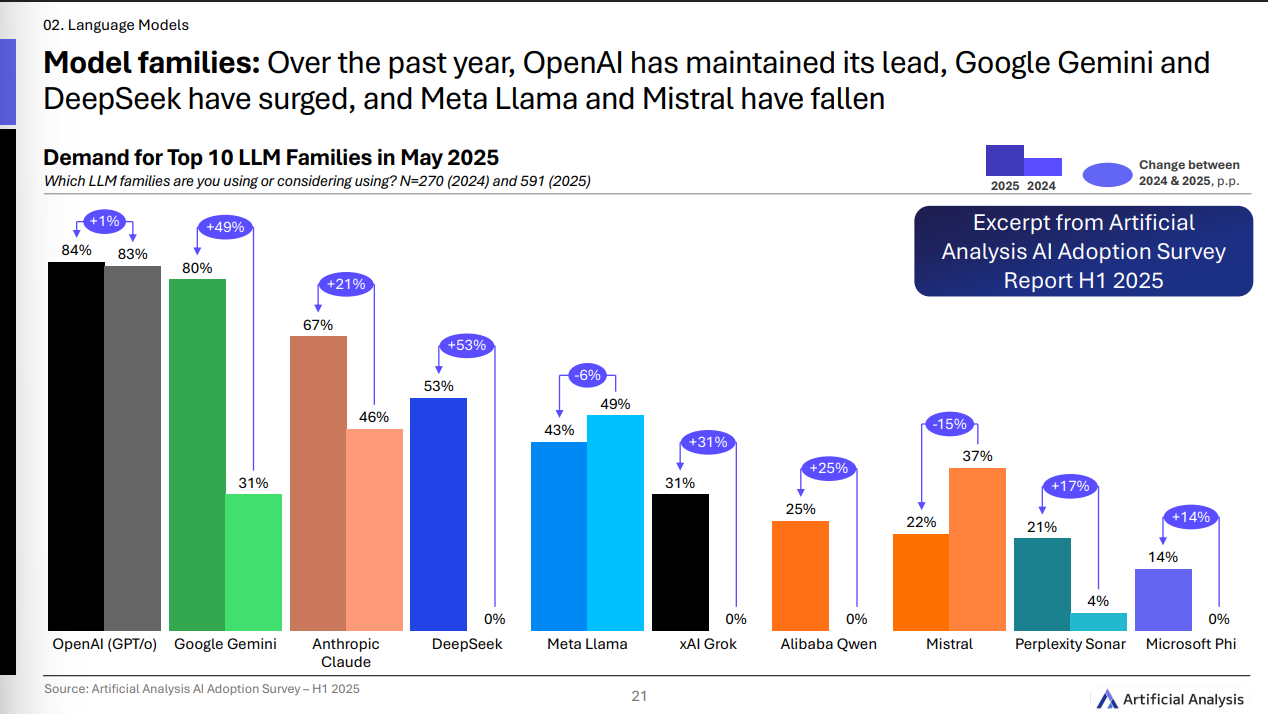
与 2024 年比, OpenAI 基本盘稳 (+1p.p.), Google Gemini、DeepSeek、xAI Grok 熱度增长明显; Llama、Mistral 略有回落。
价格在跌,但“高智价位带”更稳
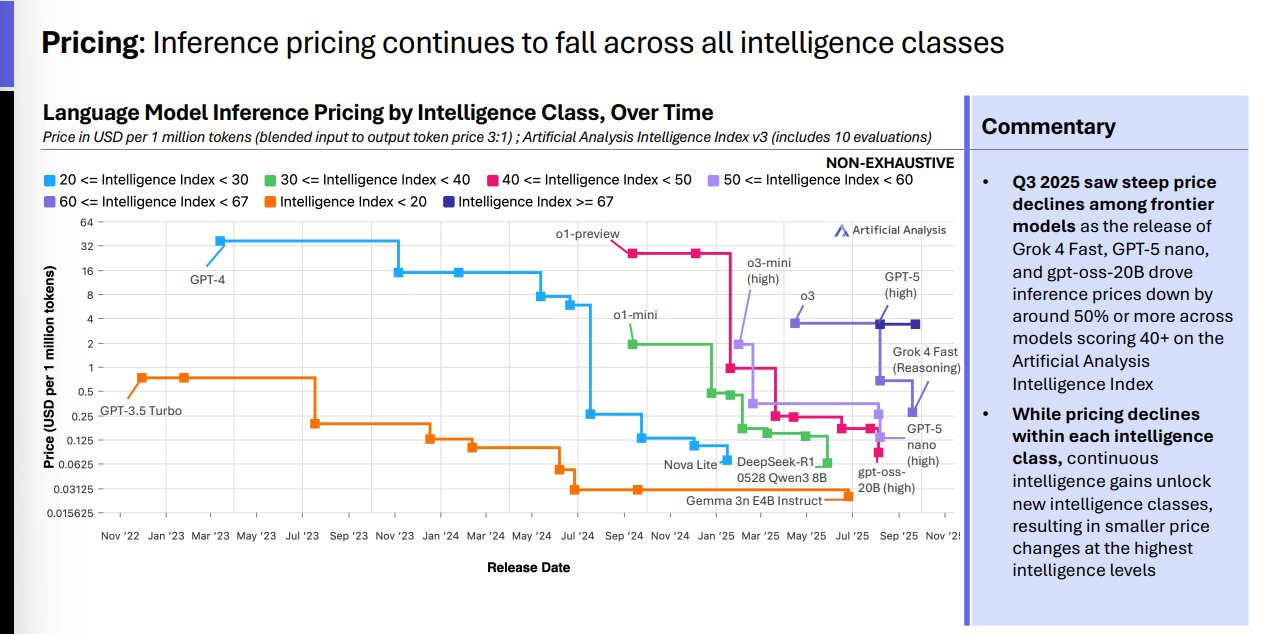
推理价格(Inference Pricing) 在各智力段位整体下降: Grok 4 Fast、GPT-5 nano、gpt-oss-20B 的发布拉动 40+ 智能指数段 的价格普遍 腰斩 。但在 最高智力带 ,因“新一档智能”不断解锁,价格降幅相对小。
开源模型正在追前沿
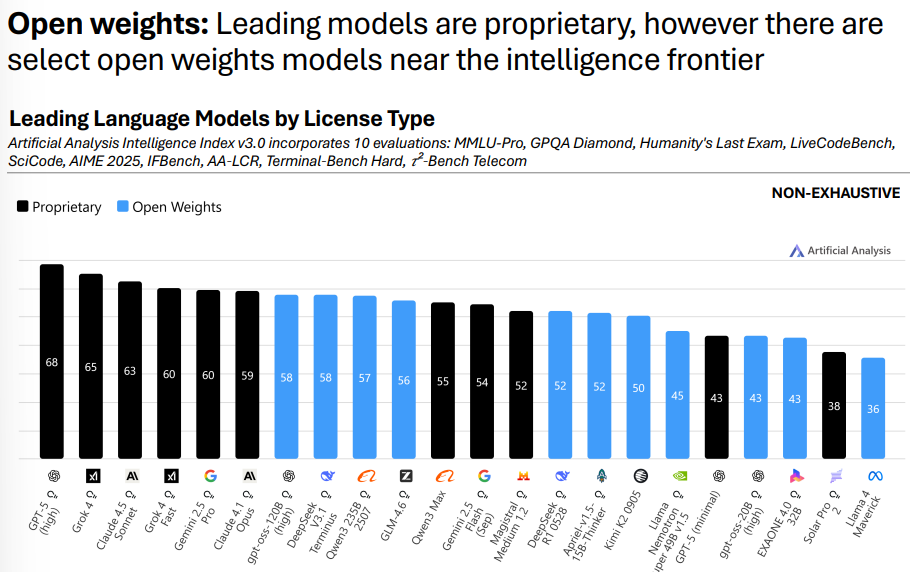
前沿仍由闭源模型领跑 (GPT-5、Grok 4、Claude 4.5 等),但 OpenAI 的 gpt-oss-120B 把美国实验室也拉回了开放权重前沿。
“推理模型”到底“更贵”在哪?
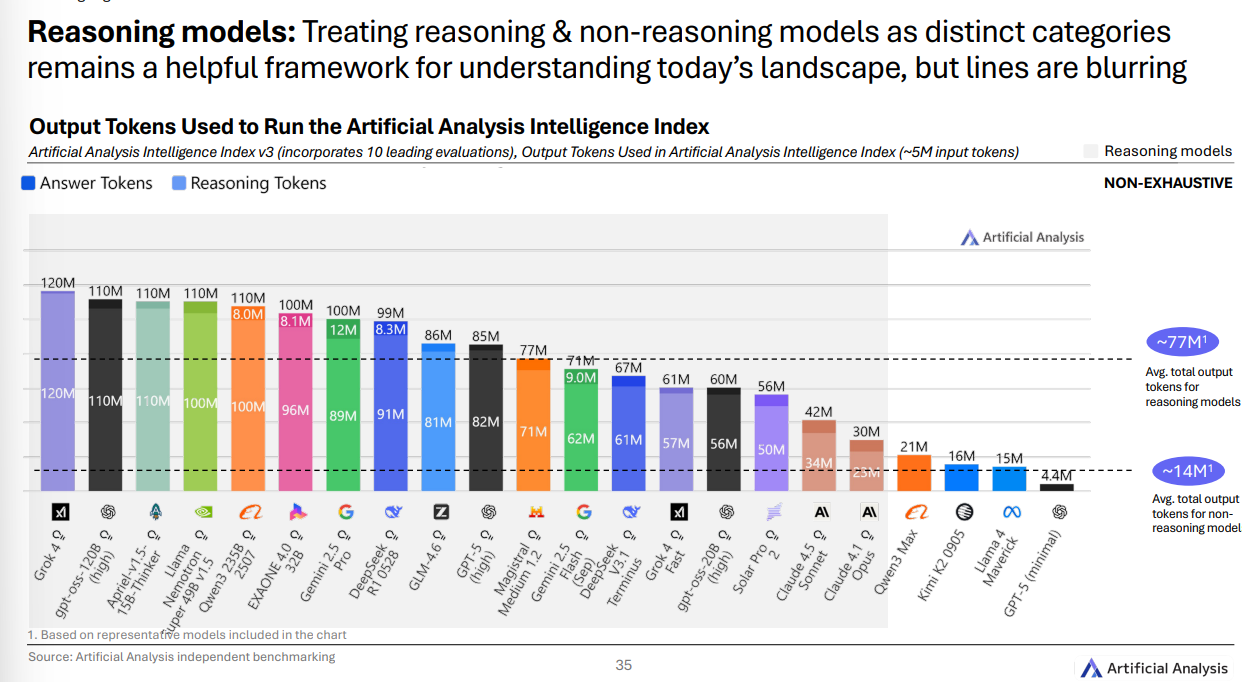
在同一套综合评测里, 推理型 模型平均要产出 约 7700 万 输出令牌,而 非推理型 平均 约 1400 万 。也就是它们会“先想再答”,因此 更费算 。
语言模型 × 智能体(Agents)
什么是“智能体”?
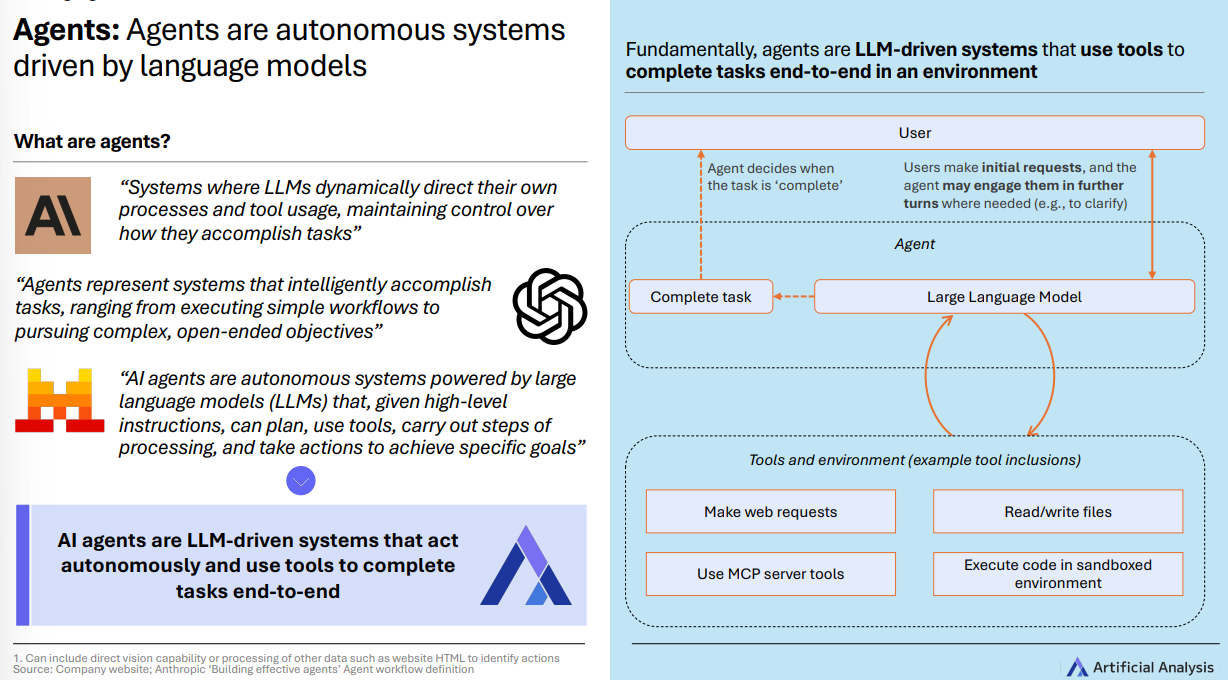
一句话: 由大语言模型(LLM, Large Language Model)驱动、能自主规划并调用工具、把任务从头做到尾的系统 。
( 注:工具 可以是“读写文件、代码执行、联网抓取、调用企业内工具(如 MCP 服务器)等”。)
Q3新模型怎么为“会用工具”而生?
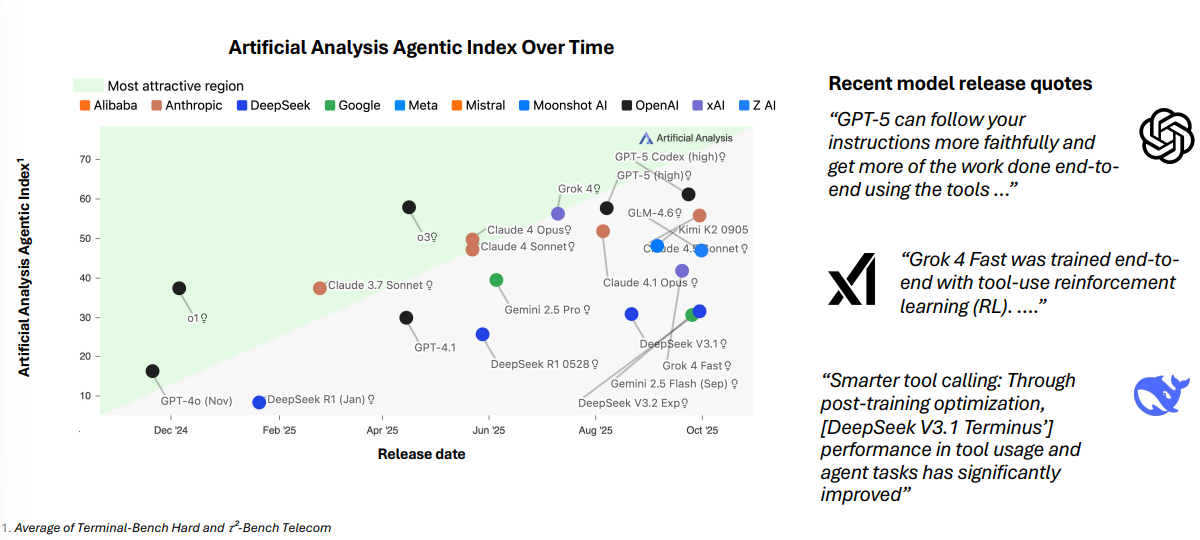
多家闭源与开放权重模型在 预训练 与 强化学习(RL) 阶段,明确针对 工具调用 与 多步任务 做了优化;报告把这类能力做成了独立的 Agentic Index ,显示近几月明显提升。(见 第41页 )
大家都在做哪些“智能体”?

编码、深度研究、电脑操作 是头部实验室聚焦的三大场景; 客户支持、销售 也有多个玩家形成竞争格局。
聊天应用正“长出”更多手脚
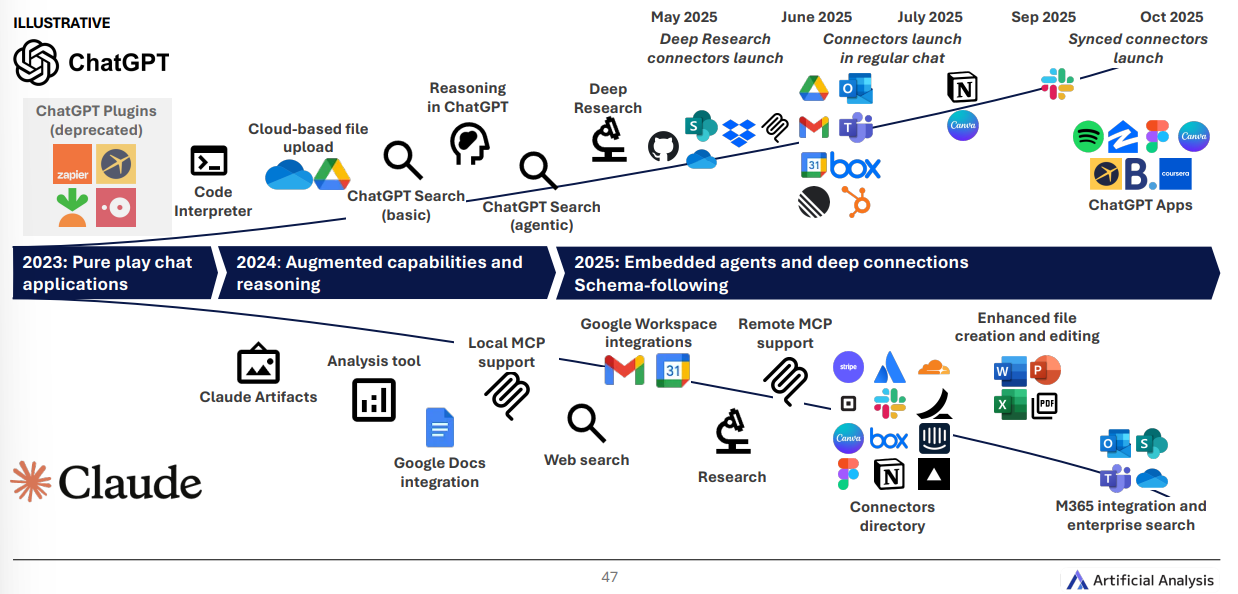
从 2023 年的“纯聊天”,到 2024 年的“增强推理”,再到 2025 年的 嵌入式智能体 + 深度连接 :网页搜索、云端文件、Google Workspace、企业搜索/连接器、代码执行、App 形态……一步步把 多步工作流 打通。
03. 图像与视频(Image & Video)
关键词: 视频快进、图像编辑出圈、音频加持
视频质量猛进 :排行榜更新很快——Q1 还领跑“图生视频”的 Runway Gen 3,如今仅列 第 23 。
图像编辑走红 :指令式编辑(用自然语言修图)成主流, Gemini 2.5 Flash(Nano Banana) 带动 iOS App 爆红;ChatGPT 的 GPT Image 1 也很受欢迎。多图输入正在成为标配。
中美两边此消彼长 : 文本生图 中, 字节 Seedream 4.0 领先, 图像编辑 中 Gemini 2.5 Flash 领先; 视频生成 方面,中国团队整体领先: Kling 2.5 Turbo 同时领跑“文生视频/图生视频”。
音频进入视频生成 : Sora 2 与 Veo 3 原生支持“带声音”的视频;带音频更贵—— Sora 2 是0.40/秒,而无音频可比模型 Hailuo 2 Pro 约 $0.08/秒 。
( 注:Elo 分数 原用于对弈评分,报告把它用来做模型竞技场排名的相对强弱指标, 数值越高代表相对更强 。)
专题一:文本生图 & 图像编辑
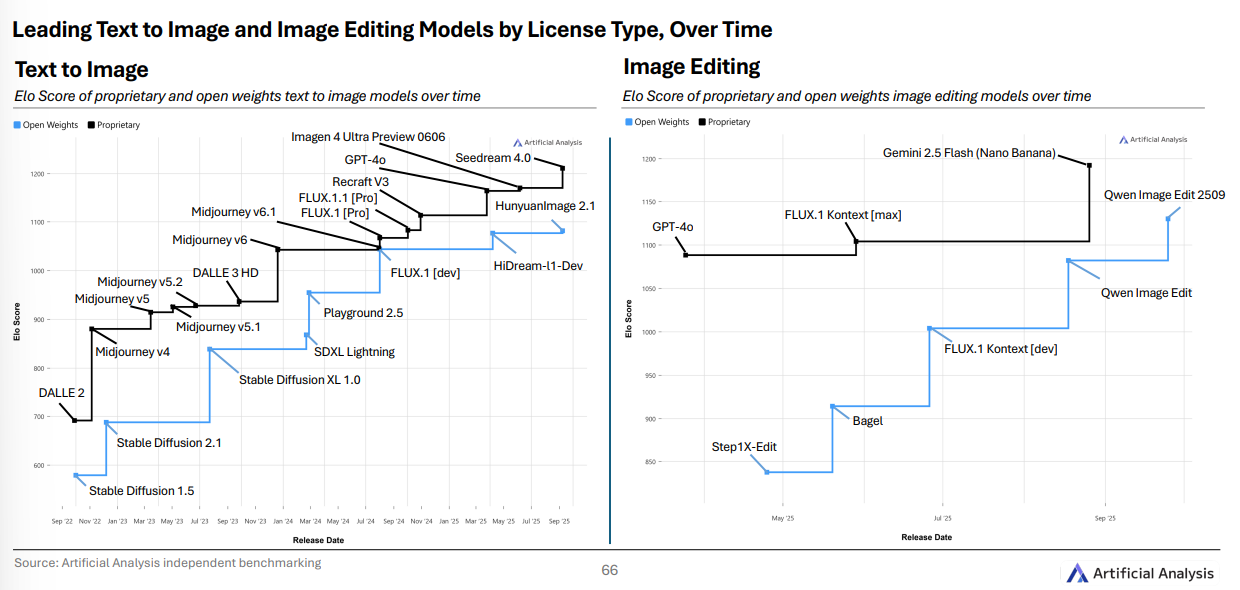
专有模型仍占优 ,但开放权重在 图像编辑 上追得更紧: Qwen Image Edit 2509 进入编辑榜 第三 。文本生图方面, Seedream 4.0 相比 Imagen 4 Ultra 提升约 30 Elo 。
专题二:视频生成
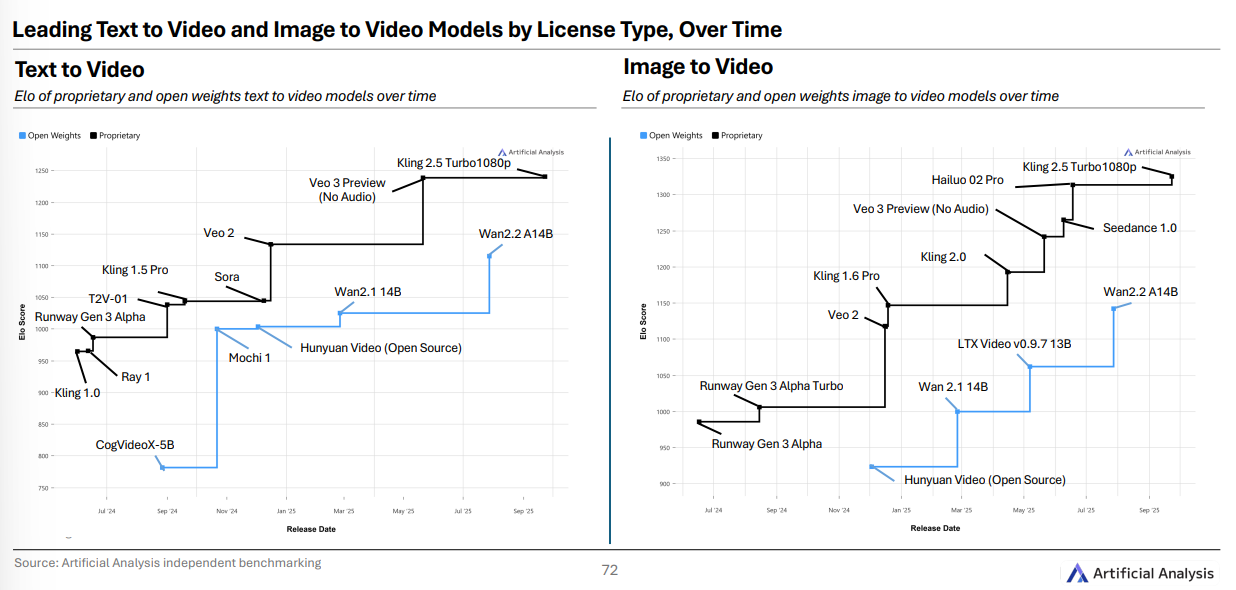
专有模型领跑,开源权重落后半步 : Kling 2.5 Turbo 稳居“文生视频/图生视频”前列,开源侧 Wan 2.2 A14B 是代表性最强者,但整体仍 滞后 。
西方模型在前十中偏少 :图生视频 Top10 里,西方模型仅 Google Veo 3 与 Luma Ray 3 两席。
04. 语音与音乐(Speech & Music)
新的准确率“金标”: AA-WER 指数
Artificial Analysis新出的 AA-WER (Word Error Rate) 用三套更贴近真实世界的数据(口音多样、行业词汇多、声学条件复杂)测 语音转写 (STT)准确率:
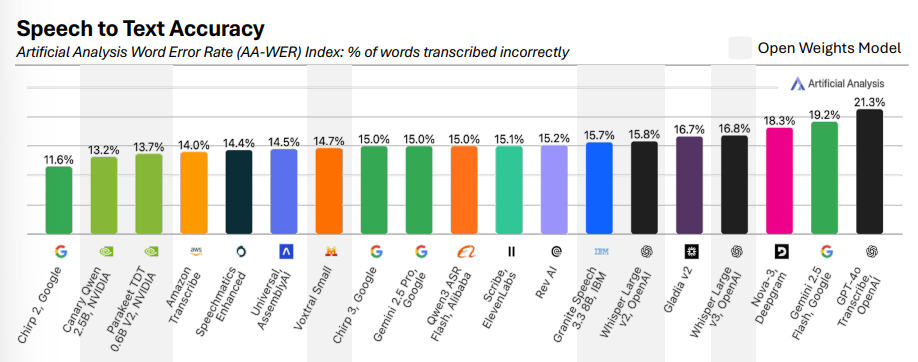
Google Chirp 2以 11.6% 领先;
NVIDIA的开放权重 Canary Qwen(13.2%) 、 Parakeet TDT(13.7%) 紧随其后;
OpenAI GPT-4o Transcribe为追求“更流畅”的可读文本, WER 偏高(21.3%) 。
(注:WER(词错误率)越低表示转写越精准。 AA-WER 按音频时长加权平均,覆盖 VoxPopuli、Earnings-22、AMI-SDM 三套数据。)
语音合成(TTS)与语音对语音(STS)
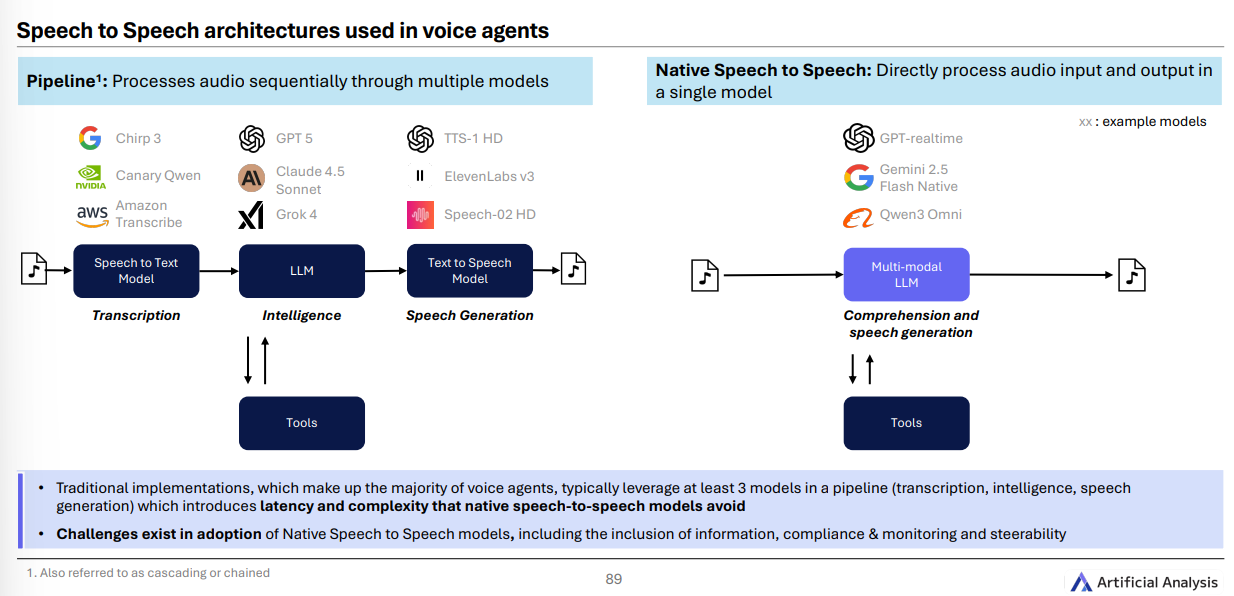
新一代 TTS 支持 情感、语气 等更细粒度控制(如 SSML 标签),但 Q3 的新模型整体尚未明显超越既有领先者。
原生 STS 模型可上生产 : Gemini 2.5 Native Audio Thinking 在“语音推理”上表现最佳;开放权重有 Qwen3 Omni Flash 加入;OpenAI 的 GPT Realtime 系列也在快速迭代。
为什么 STS 更香? 传统“转写→文本推理→合成”的“串联流水线”至少要走 3 个模型, 时延与复杂度更高 ;原生 STS 一步到位,但在 合规、可控、可监测 上仍有挑战。
05. 加速器(Accelerators)
需求与供给两端,都在抬杠
推理需求爆发 :更长上下文、更强推理与“智能体”工作流,让 单次查询算力 激增。头部实验室都经历了“算力吃紧”,出现 延迟发布、限流 等现象。
NVIDIA Blackwell全面量产 : 8×B200 系统广泛可用,机柜级 GB200 NVL72 进生产但量有限; B300/GB300 预计 年内 亮相。
系统级性能成为新战场 :不再只盯“单卡”,而是放大 同域互联(如 NVLINK) 与 多节点网络 的规模; 分布式推理 (prefill/解码拆分、专家并行、按激活频率缩放专家副本等)走向主流。
市场格局 :NVIDIA 仍主导“前沿训练”,但 AMD、谷歌、亚马逊及一众新创在推理/训练上提供差异化选项。
实测:B200 对比 H200/H100(系统负载测试)
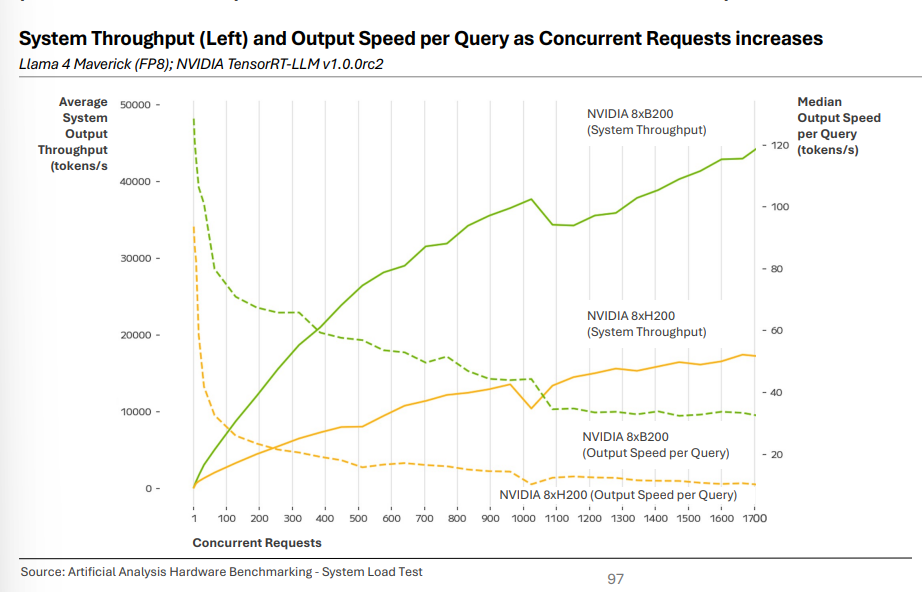
在 TensorRT-LLM v1.0.0rc2 、 Llama 4 Maverick(FP8) 场景下:
系统吞吐 : 8×B200 在 1000 并发 时约 39K tokens/s ,而 8×H200 约 13K tokens/s (约 3× 优势 )。
用户侧出字速率 :低并发下 B200 >120 tokens/s 、约 1.3× H200;高并发下 B200 ≈35 tokens/s 、约 3.5× H200(~10 tokens/s)。
(注:以上为“同系统、同软件栈、同模型”条件下的对比;真实业务还受网络、批处理策略等影响。)
报告给予每个人都有益的收获
看智能,不只看价格 :价格在降,但“会思考、会用工具”的模型每个任务更费算——选择时要按 任务复杂度/时延/成本 权衡。
场景先行 :编码、研究、电脑操作这三类“智能体”场景成熟度高、生态热闹,试点更容易见效。
基础设施别忽视 :当业务放量, 分布式推理与系统级优化 往往比“换大卡”更值当。
参考与致谢
本文全部事实、数据与图示来源: Artificial Analysis State of AI – Q3 2025 Highlights Edition 。
( 如需更详细的模型榜单需查阅报告完整版请联系报告出品方。如需 Artificial Analysis State of AI(Q3 2025 精选版)可后台私信。 )