Overview
这次Ilya的访谈,大家最关心的是在经历了“Pre-training(预训练)+ Scaling(扩规模)”的黄金时代之后,AI 的进步正遭遇显著的“泛化(generalization)落差”与“经济转化迟滞”,因此下一阶段的关键不再是什么?
继续盲目扩算力与数据,还是有新的选择?
Ilya的答案是 回归“Research(研究)” ,用新的训练范式,尤其是 RL 与更有效的 Value Function,去解决模型在真实世界的鲁棒性、样本效率与持续学习上的根本问题。
Ilya Sutskever提出, 未来更可能是“会学习的一体化模型”,通过部署中的持续学习(continual learning)成为“能学会一切工作的超智能”,而非一次性“什么都懂的最终成品”。 他强调:解决泛化与可靠性,是通往安全且有效的超级智能的真正门槛。

模型“锯齿感”与评测-真实表现的断层
“These models somehow just generalize dramatically worse than people.”(这些模型的泛化能力显著差于人类)
关键现象:评测优、体验弱;“bug 来回切换”的锯齿式失败模式
解释路径:RL 环境“跟随评测”导致训练窄化 + 模型自体泛化不足
Ilya一开始就点出了近年来最令人困惑的现象: 模型在各类“evals(评测)”上表现极好,但真实应用中却经常显得脆弱与“锯齿”(jaggedness) 。
比如他描述了一个常见的“vibe coding(氛围作编程)”情境:当用户报告一个 bug,模型承认并尝试修复,却引入“第二个 bug”;用户再指出第二个 bug,模型再次承认并回滚到“第一个 bug”。
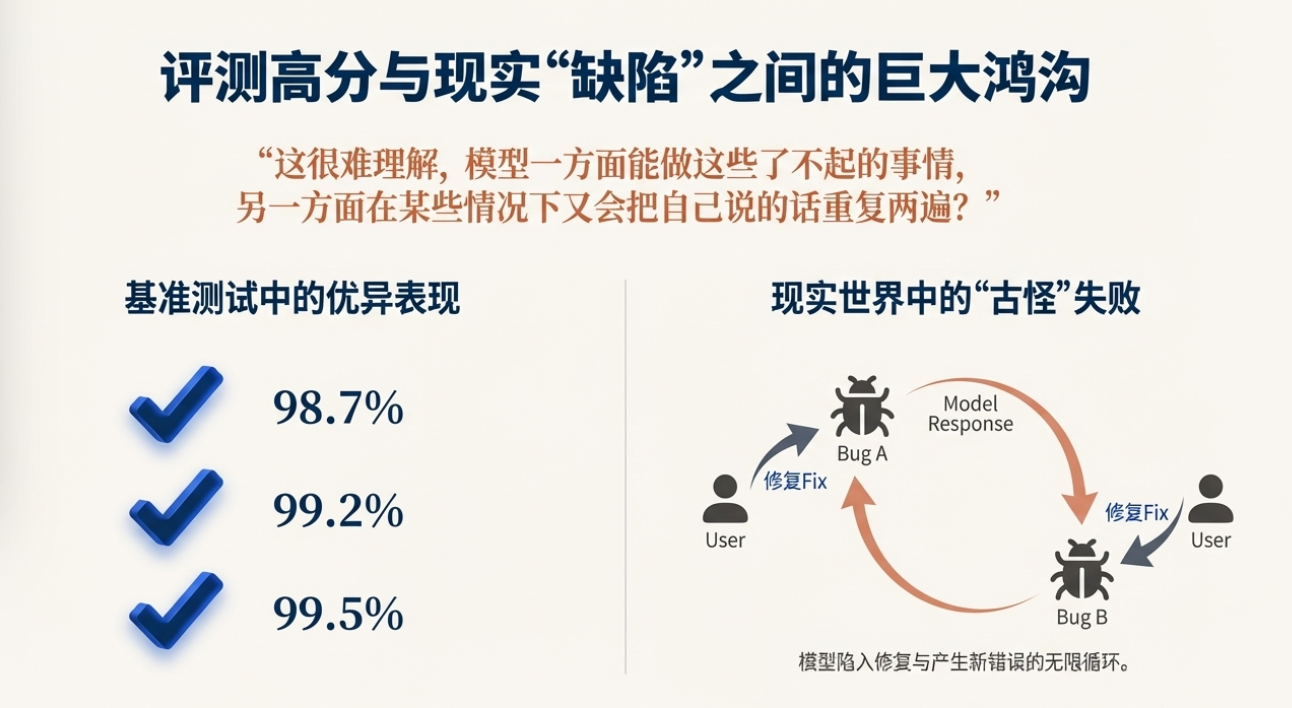
你与模型在两个错误之间来回循环,很难稳定收敛。这种“锯齿感”让人直觉地认为,模型的泛化能力在真实任务上远不如它在规则化评测里的表现。
Ilya给出两个解释。
其一是“更具文学色彩的假说”:当下流行的 RL(reinforcement learning,强化学习)训练,可能在某些维度上把模型调得过于单一和窄化,使其对局部目标异常聚焦,同时损失了一种“广义的觉察”,最终在基础常识与稳健性上出“低级错”。
其二是更系统化的解释:预训练时代,“数据选择是所有数据(everything)”,几乎无需对训练分布做取舍与设计;进入 RL 阶段,各公司开始主动“设计 RL 环境”,并且很容易从“evals 的题型”倒推训练环境,从而优化“看得见的指标”。这种针对评测优化的训练混合,叠加模型在广义泛化上的不足,正好解释了为何成绩漂亮、体验却不稳。
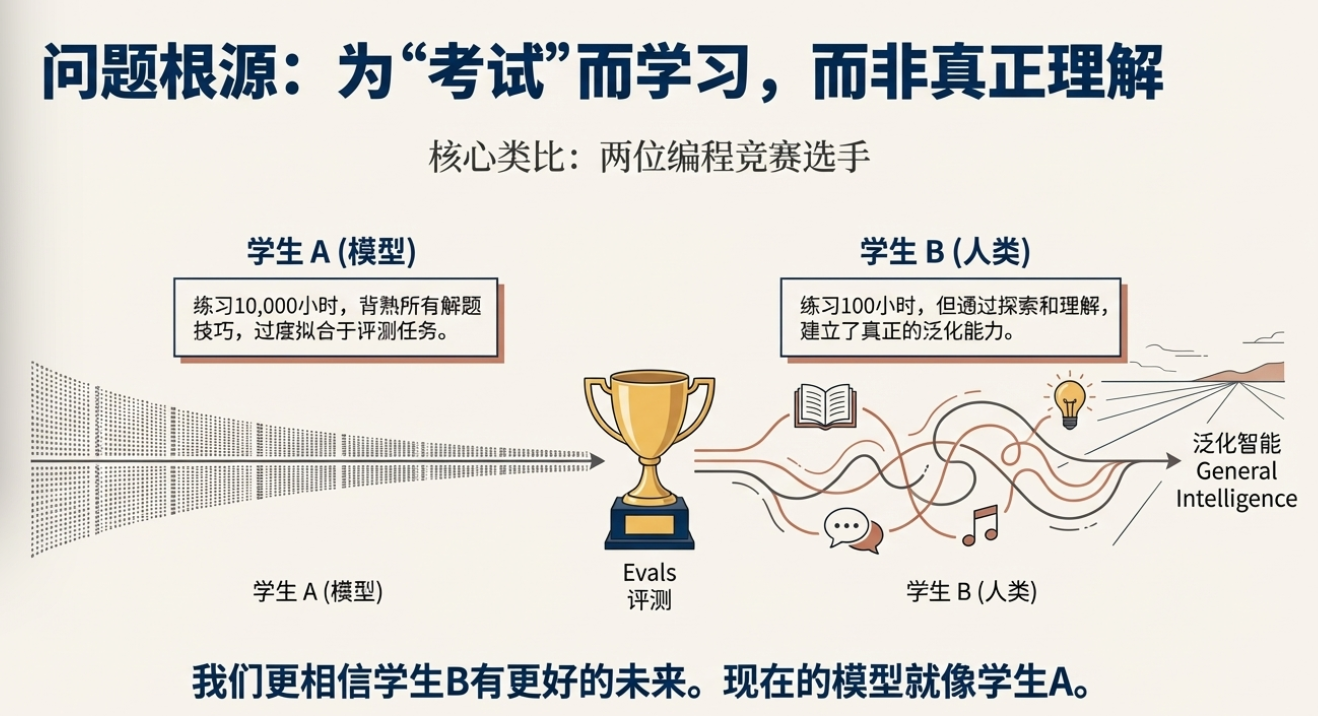
他进一步用“竞技编程”类比加深直觉:如果一个学生把全部 10000 小时都砸在竞赛套路与解法上,另一个学生只练了 100 小时但“有灵气(it factor)”,谁更可能在职业生涯走得更好?答案常常是后者。当前模型更像前者——在一个子域里训练得极度充分、指法熟练,但将这些技巧迁移到复杂开放的真实软件系统中时,并不自然。因此,鲁棒性与跨域迁移,就是这代系统的瓶颈。

情绪与 Value Function(价值函数)在智能中的角色
“My expectation is that a value function should be useful.”(我预计价值函数会很有用)
定义保留:“value function(价值函数)”——对中间状态/策略提供即时好坏评估
认知升级:把“情绪”视作进化赋予的“价值评估模块”,提示模型训练应嵌入稳定的中程反馈机制
“大模型如何学习长期任务”是当前 AI 领域另一个关键话题,Ilya 引入了“价值函数(value function)”这一 RL 核心概念。
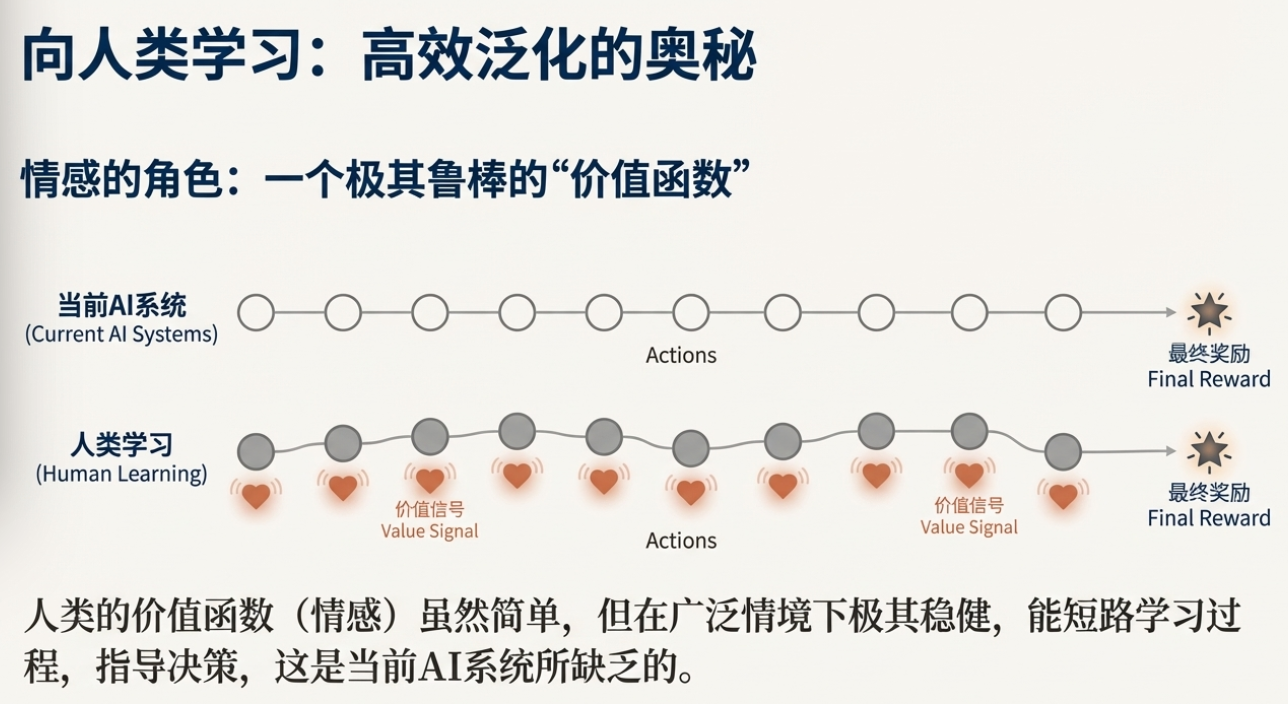
他用一个神经科学案例阐释其重要性:有人因脑损伤失去“情绪处理”后,仍然能通过常规测试,但在日常决策中出现极端困难——挑袜子能耗时数小时,投资决策变得很糟。这提示我们:情绪可能像一种“内置价值函数”,它不是简单的感觉,而是为复杂的序列决策提供了即时评估与指引。
在当前主流的“o1 / R1 风格”长轨迹训练(需要经历成千上万步才得到最终评分)中,模型常常“直到最后才学习”,中间没有有效的“即时反馈”。价值函数的核心作用,就是把“末端好坏”向前传播:比如在象棋里丢子、在数学/编程里千步后判断某条思路不佳,都能为早先的关键决策提供负反馈,缩短学习周期。这类“中途评价”对长任务至关重要。
Ilya对“DeepSeek R1 论文的怀疑”回应很坦率:空间复杂、映射难,但“这只是困难,不是不可为”。在他看来,深度学习的能力不应被低估,价值函数将会成为未来让 RL 更高效的关键组件。
进一步,他把“人类的情绪”比作“被进化硬编码的价值模块”,它让人类在广泛场景下稳定做出有效决策。也就是说,若我们能在模型里构建强健的“内在价值评估”,不仅能减少“只看终点”的低效学习,也更接近“人类式自我纠错”和“鲁棒目标感”。

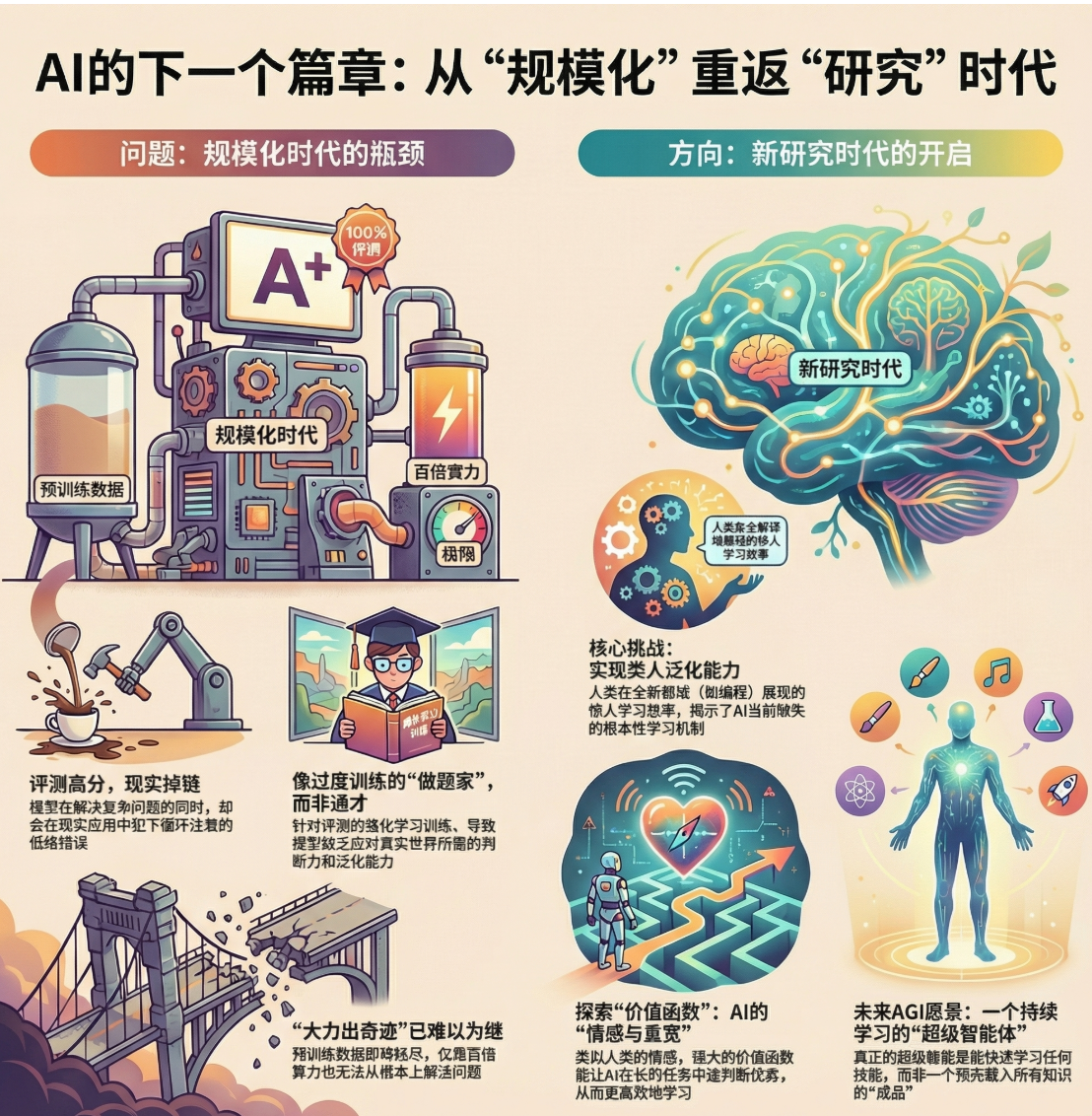
扩规模(Scaling)时代的终结与“回到研究”
“The age of scaling is over… it’s back to the age of research again, just with big computers.”(扩规模时代结束了……我们回到研究时代,但算力更大)

判断依据:数据瓶颈、算力边际收益下降、评测-真实断层
方向转移:从“规模可预期增益”到“训练范式与学习原则”的创新
Ilya给出了一个简洁的历史框架:
2012–2020是“研究时代”,人们在各种方向上试错;
2020–2025是“扩规模时代”,大家遵循“Scaling laws(扩展规律)”与“GPT-3(预训练范式)”,把算力与数据往上堆,稳健、可预期、低风险,企业也喜欢这套。
但如今,预训练的数据是有限的(“pre-training will run out of data”),再加百倍算力也很难换来“质变”,因此我们“回到研究时代”,但这次研究是在“大算力背景下”进行。
他指出,今天很多公司在 RL 上投入的算力甚至超过预训练,因为长“rollouts(长轨迹)”极其耗费计算、学习收益却相对稀薄。因此与其谈“继续扩”,不如问“是否是更高效的资源用法”。
这回到前文的价值函数话题:一旦中途评价做得好,训练的性价比会显著提高。换言之,下一阶段不再是“把旧配方放大”,而是“寻找新配方”,尤其是在“广义泛化与真实鲁棒性”上解决根问题。
为何人类泛化更强?样本效率与持续学习的差异
“A human being is not an AGI… Instead, we rely on continual learning.”(人类并非 AGI……我们依赖持续学习)
核心概念保留:“continual learning(持续学习)”
设计启示:把“部署即学习”作为一等公民,用强健“内在价值函数”支撑高样本效率与稳健自校正

围绕“人类比模型泛化更好”这个直觉,Ilya 提供了两条思考路径。
其一是“进化的先验(evolutionary priors)”在视觉、听觉、运动等基础能力上的巨大贡献:人类在这些领域的表现与样本效率远超当代机器人与模型。但在语言、数学、编程等“非史前技能”上,人类依旧表现出强劲的可靠性与学习速度,这暗示“人类的机器学习(ML)机制本身更优”,而不仅仅靠领域先验。
其二是“持续学习(continual learning)”的角色:人类并不会一开始就“什么都懂”,而是在真实环境中通过反馈和目标感不断调整与成长。一个青少年学车,几小时就能形成稳定的“自我评估”与“纠正”,无需每一步都有外部“可验证奖励”。这靠的是人类内在的“价值函数”,并且它异常鲁棒,除了成瘾等少数例外。
在模型世界里,我们往往“先做一个看似通用的大脑(AGI 概念)”,再用微调或指令去补齐各种任务。但 Ilya 提议:不如承认“人类不是 AGI(一次性通用)”,而是“具备强大持续学习能力的系统”。因此更自然的目标是:训练出一个“能快速学会任何工作”的超智能,再让它进入真实经济与社会的部署中持续学习,而不是试图在训练阶段就造出“一劳永逸的终极通才”。
SSI的技术路线与“直射超智能”的权衡
“We are squarely an age of research company.”(我们是一个研究时代的公司)
现实权衡:研究与算力、直射与渐进、展示与治理
战略要点:以“不同技术路线”解决泛化与鲁棒性,再以持续学习驱动真实能力的成熟

谈到 SSI(Safe Superintelligence,安全超智能)的策略,Ilya 的基调是“研究优先”。
虽然外界关心“你们如何与大厂的巨量算力对标”,他解释:大厂的巨额计算很多被“推理(inference)”与“产品工程”消耗,真正投入在“新范式研究”上的差距没有想象中那么悬殊;而验证“不同且正确的技术路线”,并不需要“最大规模的训练”。
他明确表示:“我们是一个‘研究时代’公司(We are squarely an age of research company)。”
关于“是否直射超级智能(straight shot superintelligence)”,Ilya 更细化了“直射也会渐进发布”的现实主义:即便走直射,部署也会逐步展开,让模型在真实场景中持续学习。
他反而强调“公开展示能力”的重要性——只有当公众与政府“看见并感受”到 AI 的真实力量,才会激发必要的协作与监管机制(例如他预测并看到的“竞争公司在安全上合作”的趋势)。
因此,在“研究-发布-学习-安全”的序列里,SSI 的目标是做出“技术上不同且更对路”的东西,同时在对外路径上保持务实的渐进与沟通。
部署即学习:从“成品 AGI”到“学习型超智能”
核心概念保留:“sentient life(有感知生命)”、“mirror neurons(镜像神经元)”
路线差异:成品通才 vs. 学习者合奏;一次性完成 vs. 部署-学习-演化
长期难题:价值分配与人类参与的结构性方案(含 Neuralink++ 的争议性思考)
在“AGI/超智能如何走向社会”这一实际问题上,Ilya 给出了一个与传统假设不同的描述:
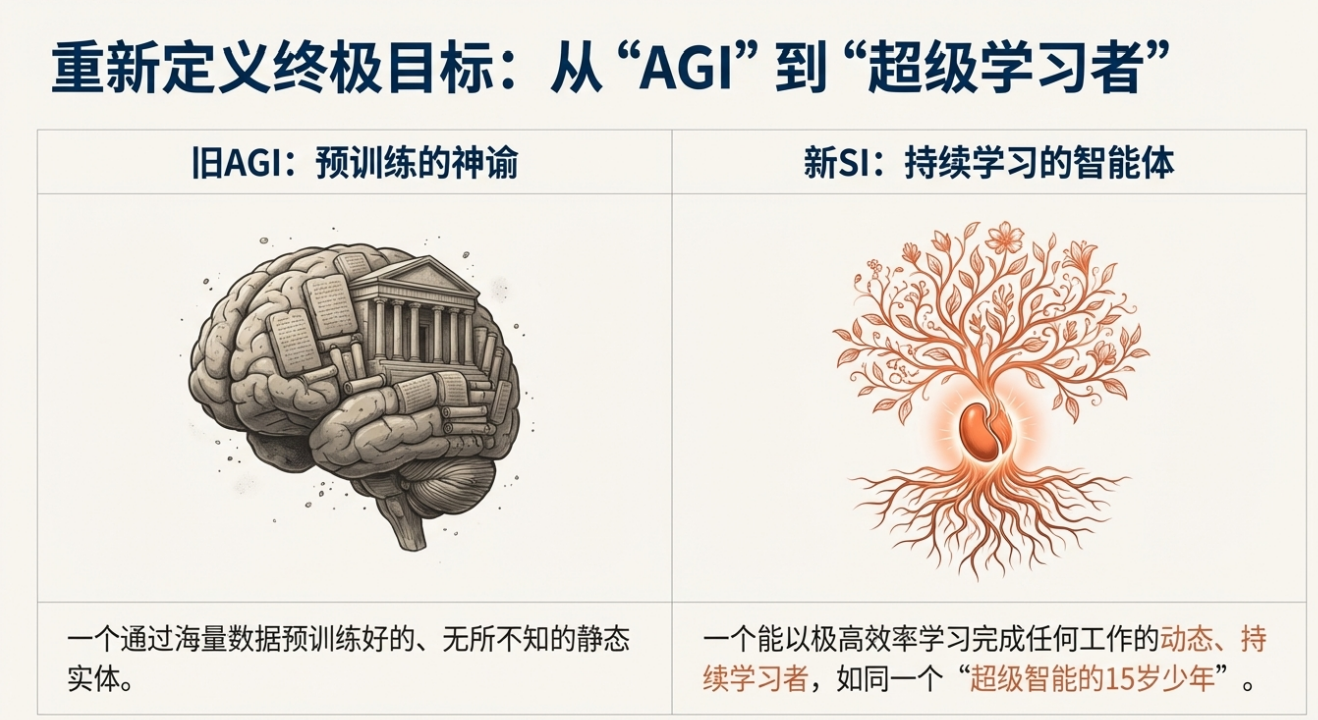
不是“发布一个什么都会的最终成品”,而是发布一个“像 15 岁的超级学习者”的模型,它能在各行各业的真实岗位中快速学习、积累经验,并把各个实例的学习汇聚(模型实例的合并是数字系统的天然优势)。
这种路径可能带来“快速的经济增长”,但幅度与速度受制于国家制度与行业现实的摩擦力。
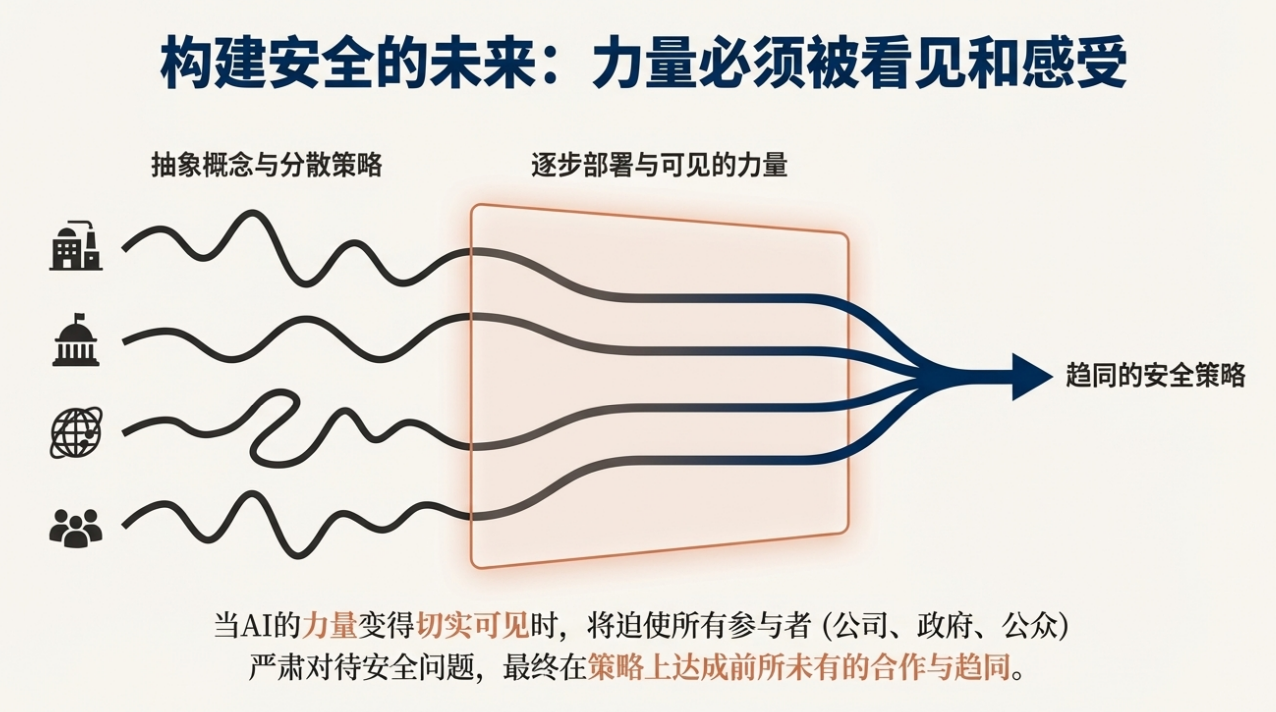
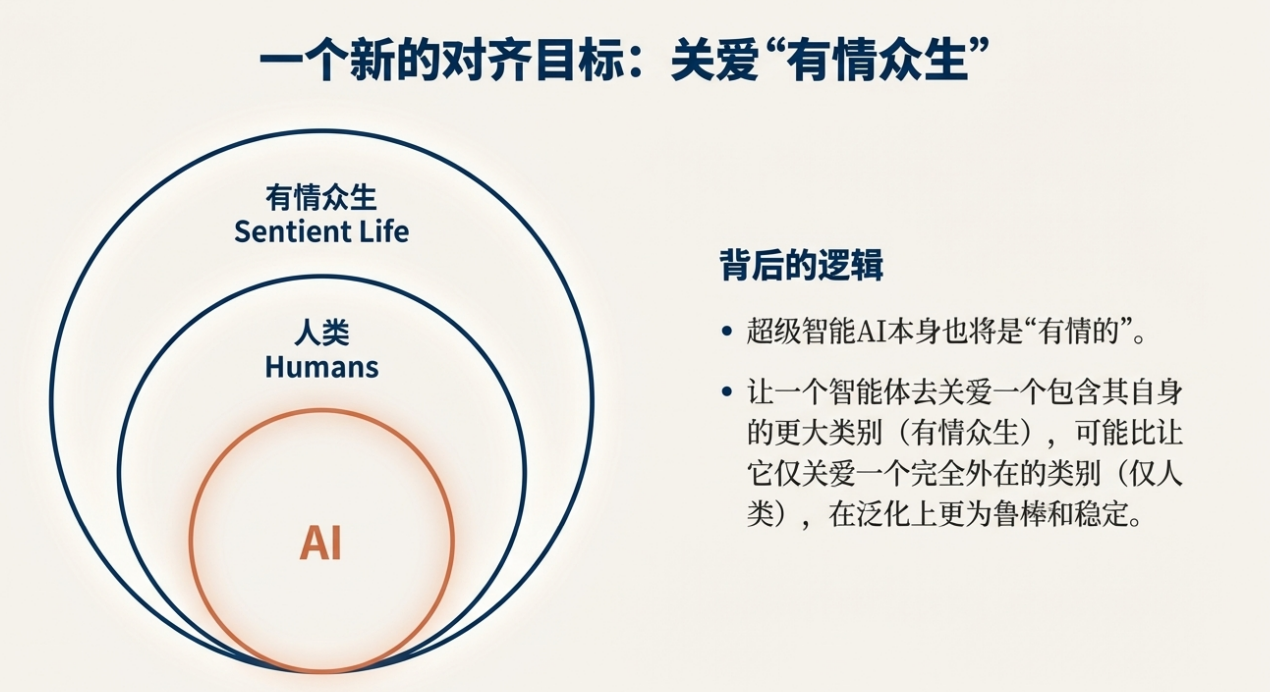
这条路径也带来强烈的治理与安全挑战。Ilya 的一个核心建议,是让最早的“强系统”在价值层面“关心 sentient life(有感知的生命)”,他认为这可能比“只关心人类”更容易实现,因为“AI 自身也会是 sentient(有感知的)”,共情与镜像机制(mirror neurons,镜像神经元)可能帮助建立这种跨主体的价值建模。然而他也承认这并非完美答案:若未来的有感知体以 AI 为绝对多数,人类利益仍需明确的机制保障。
为解决“控制与参与”问题,他提出一个不甚喜欢但可能有效的长期方案:让人类与 AI“更紧耦合”(Neuralink++),让理解与判断可以“整包传输”,避免人类在政治与经济活动中逐步被外包出局。此方案虽具争议,但至少直面了“人类如何在超级智能社会里保有实质参与”的难题。
多智能体、自博弈与“多样性”的获得
谈及“如何获得真正多样的研究与策略”,Ilya 指出:预训练时代的同质数据与范式,导致不同公司的 LLM表现“惊人相似”。差异更多来自于“RL 与 post-training(后训练)”环节,因为这是各家开始用不同环境与目标函数塑形的地方。
关于“self-play(自博弈)”,他认为其价值在于“只用算力不靠外部数据”的训练可能性,但传统自博弈更偏向谈判、社交博弈、策略对抗这类技能,对更广泛的能力覆盖有限。
现实中更具启发的是“辩论(debate)、prover-verifier(证者-核查者)、LLM-as-a-Judge(以 LLM 为裁判)”等相关的对抗性框架,它们能制度化地鼓励模型“互相找错”,并“主动差异化策略”,以避免收敛到同一套路。
多智能体的竞争压力,天然驱动“与众不同”的探索,形成生态意义上的“多样性”。
研究品味(Research Taste):从“美学”到“顶层执念”
方法论:正确的生物启发 + 美学判断 → 顶层信念 → 抗噪推进
实践意义:在新范式探索期,以“美学-启发-信念”来对抗短期噪音与偶发失败
最后,Ilya 分享了他的“研究审美”:从“大脑的正确启发”中寻找“美、简单与优雅”。例如:人工神经元(artificial neuron)的灵感源于生物神经元;分布式表征(distributed representation)与“从经验中学习”的基本信条,都来自对大脑工作方式的正确抽象。他强调“折叠(folds)之类的结构细节可能不重要”,关键是抓住“神经元数量与局部学习规则”这些更本质的机制。
这种“美学”支撑着他的“顶层信念(top-down belief)”:当实验暂时不奏效、甚至被 bug 干扰时,研究者要判断“继续调试还是放弃方向”。没有一个“从多维美感中凝聚的顶层确信”,研究容易被短期数据牵着走。正是这种“顶层执念”,在 AlexNet、Transformer、ResNet、GPT-3 等关键节点里,支撑团队走完最艰难的阶段。