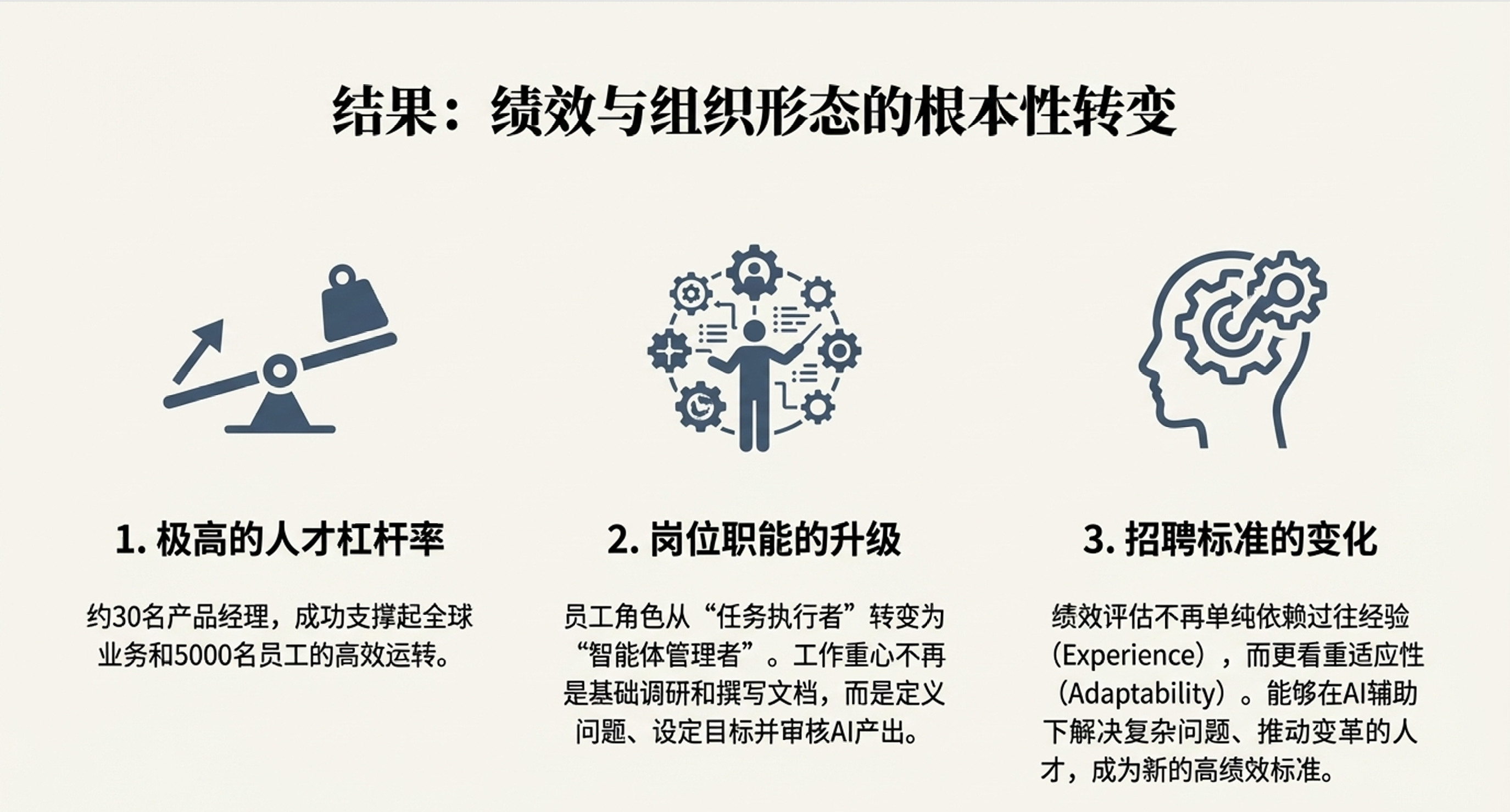
OpenAI企业产品负责人Nate Gonzalez与其AI智能体研究负责人Josh Tobin近期披露了公司内部的运营细节。OpenAI仅依靠约30名产品经理(PM)就支撑起了拥有5000名员工、服务92%财富500强企业的庞大业务体系。这一极高的人效比,源于其内部对“AI数字员工”的系统化设计与深度部署。本文将拆解OpenAI内部AI智能体的构建逻辑、核心业务场景及其实际带来的效能变革。
一、 设计与部署:从“辅助工具”到“可靠实体”
OpenAI在设计和部署内部AI智能体时,核心目标是将AI从单纯的“有用(Utility)”升级为业务流程中“可靠(Reliability)”的实体。

1. 技术构建:端到端训练与自我纠错
早期的AI应用多基于LLM API构建固定工作流,容易出现“错误累积”——即单一步骤的微小偏差导致整个任务链崩溃。OpenAI为此采取了更底层的技术策略:
端到端训练(End-to-End Training): OpenAI不再将模型仅视为文本预测器,而是针对完整任务流进行训练。模型被设计为在真实、动态的环境中运行,而非仅在静态测试中表现良好。
强化学习(RL)驱动的韧性: 引入强化学习机制,赋予智能体识别失败并重试的能力。例如,当搜索结果不符合预期时,智能体不会直接输出错误结论,而是会像人类一样更换关键词重新检索,直到获取有效信息。这种“自我纠错”能力是AI从玩具变为工具的关键。
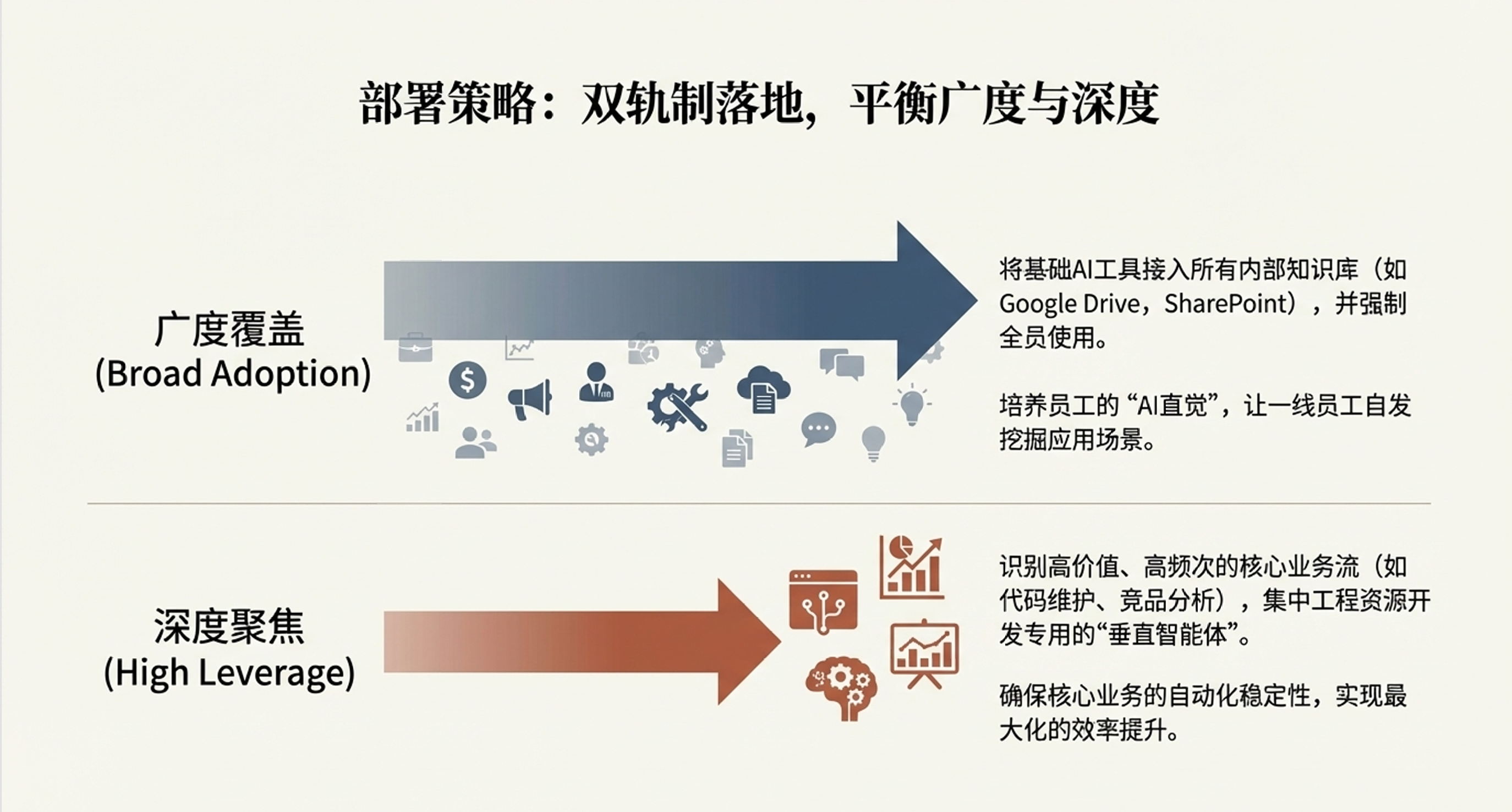
2. 部署策略:双轨制落地
在公司内部推广时,OpenAI采用了“双轨制”部署方法,以平衡普及率与业务深度:
二、 核心业务场景与数字员工职能
OpenAI内部已形成了几类标准化的“AI数字员工”,分别承担初级工程师、分析师和运营专员的职能,具体场景如下:
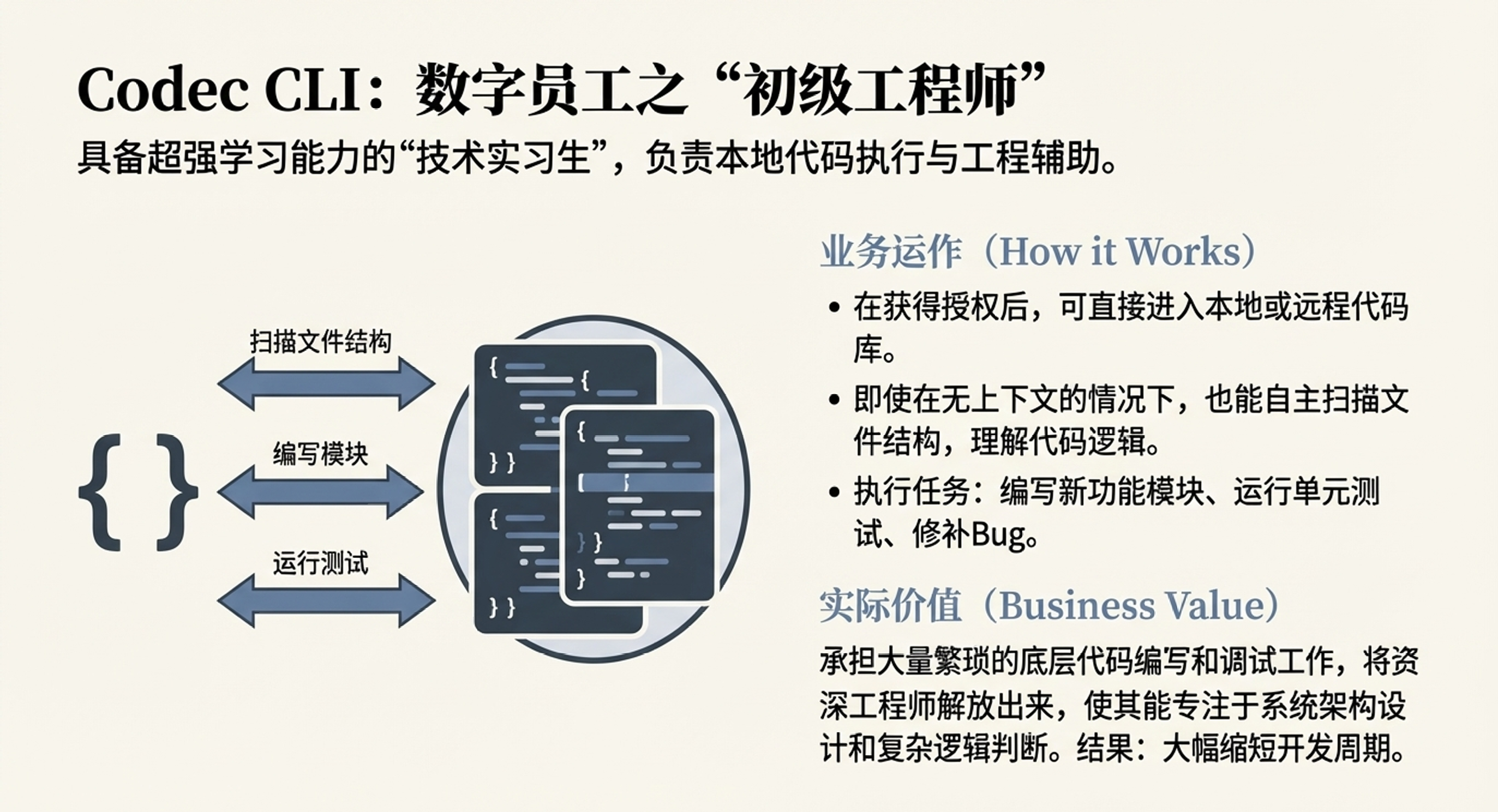
软件研发场景:Codec CLI(初级工程师)
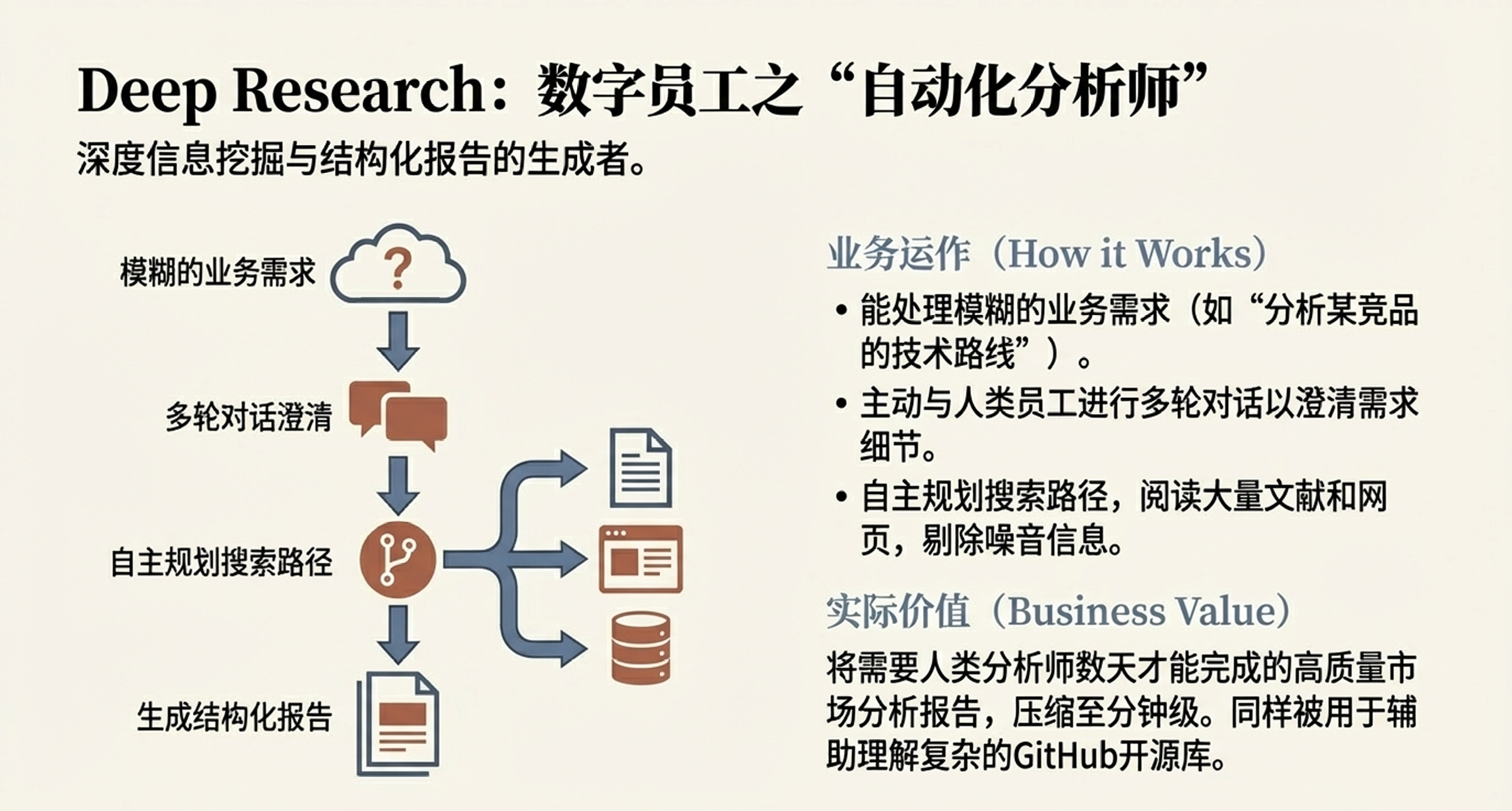
市场研究场景:Deep Research(自动化分析师)
业务运营场景:Operator(运营专员)

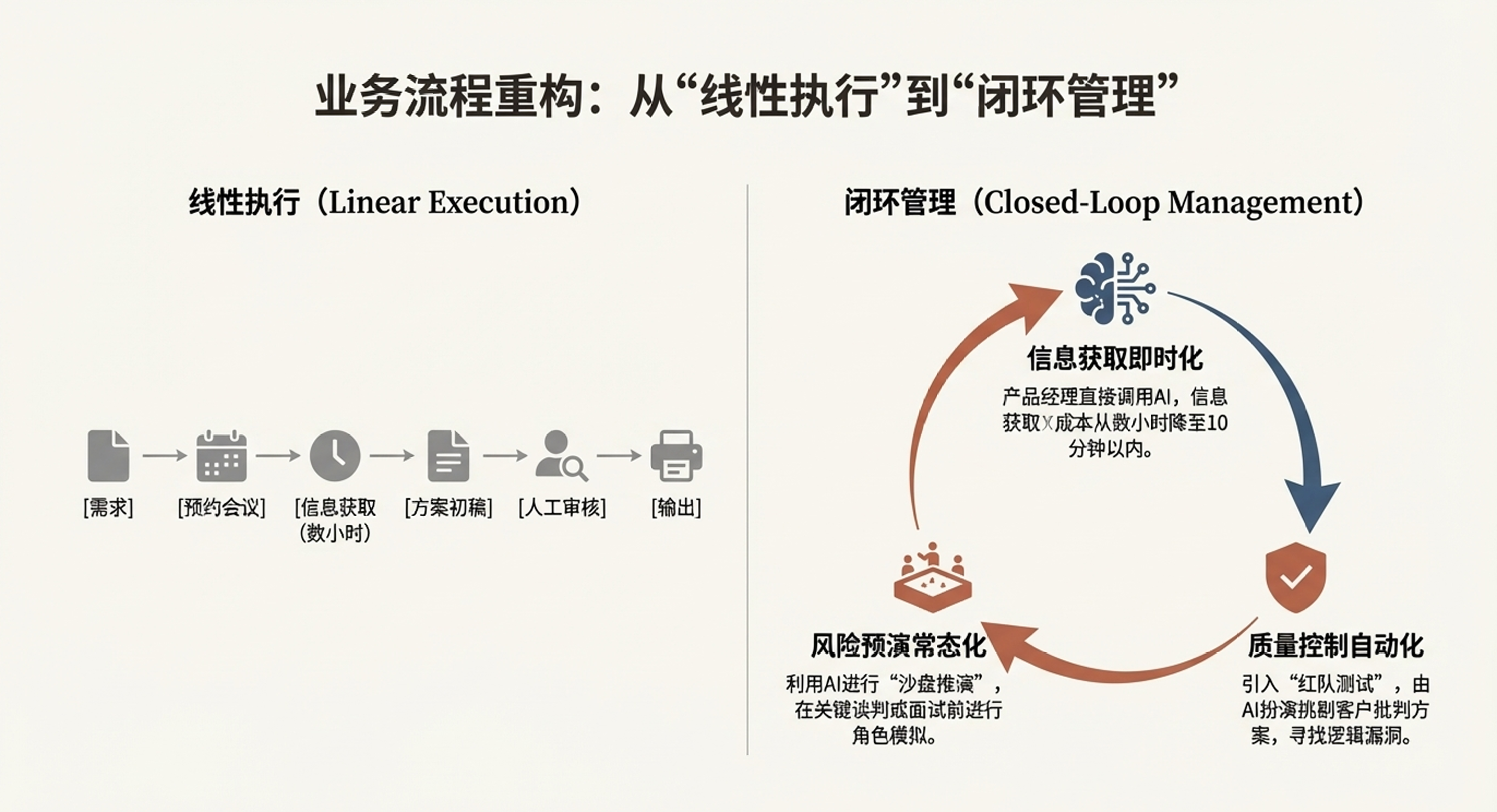
三、 业务流程重构与绩效变化
引入AI数字员工后,OpenAI内部的工作流发生了本质重构,直接推动了业务绩效和组织形态的转变。
业务流程重构:从“线性执行”到“闭环管理”
2. 绩效与组织形态变化